Original Link: https://www.anandtech.com/show/8935/geforce-gtx-970-correcting-the-specs-exploring-memory-allocation
GeForce GTX 970: Correcting The Specs & Exploring Memory Allocation
by Ryan Smith on January 26, 2015 1:00 PM EST
Over the weekend we reported on a statement released by NVIDIA regarding recent concern over unusual VRAM allocation and VRAM bandwidth performance from the GeForce GTX 970. In brief, various GTX 970 owners had observed that the GTX 970 was prone to topping out its reported VRAM allocation at 3.5GB rather than 4GB, and that meanwhile the GTX 980 was reaching 4GB allocated in similar circumstances. All of this was at odds with what we thought we knew about the cards and the underlying GM204 GPU, as the two cards were believed to have identical memory subsystems.
In their statement, NVIDIA confirmed that this unusual behavior existed, and that it was due to the GTX 970 possessing “fewer crossbar resources to the memory system” than the GTX 980. Furthermore due to this, the VRAM on the GTX 970 was segmented in a way it’s not on the GTX 980, with 3.5GB of the 4GB serving as one high priority segment, and the final 512MB serving as a low priority segment. The rest of NVIDIA’s statement then focused on performance, and why they believed this design would not have a significant performance impact versus a GTX 980-style non-segmented memory structure.
However because NVIDIA’s statement was intentionally high-level – it was meant to be accessible to the wider press and their readers, and not just the technical press such as ourselves – this meant that the statement offered few technical details on what was going on under the hood, which makes it difficult for us to validate NVIDIA’s claims and on a more human level we’re always dissatisfied with half of an answer.
As a result we’ve been digging into this issue over the weekend, working to collect the final pieces of the puzzle. To that end NVIDIA reached out to us Sunday evening to fully explain the issue at a level of detail necessary for our level of depth, making available to us a “triage team” of sorts of technical marketing, product management, and engineering/architectural personnel to answer questions and to better explain the issue. While there’s still some benchmarking left to do on our end – we’ve only had a relatively brief Sunday evening to work with NVIDIA’s full explanation – at this point we feel like we have a solid grasp of what’s going on with the GTX 970, how its memory segmenting and allocation work, and how it can impact performance.
Now make no mistake, NVIDIA right now is in full damage control mode due to the negative press this issue has garnered and the pain that’s going to follow. When NVIDIA is getting Senior VPs like Jonah Alben on the phone with us on a weekend night to talk architecture and answer questions, this isn’t normal operating procedure for the company. But at the same time it’s a positive sign for how serious NVIDIA is taking our concerns, and meanwhile an NVIDIA under pressure is an NVIDIA that is more likely to answer our deepest technical questions, giving us more insight than ever before into GM204.
GeForce GTX 970: Correcting the Specifications
To kick things off, we need to start at the very beginning and talk about the specifications of the GTX 970 itself. Everything that follows is derived from how the chip is configured, so we cannot go any farther until we understand the true configuration of the GTX 970.
| NVIDIA GPU Specification Comparison | |||||
| GTX 980 | GTX 970 (Original) | GTX 970 (Corrected) | |||
| CUDA Cores | 2048 | 1664 | 1664 | ||
| Texture Units | 128 | 104 | 104 | ||
| ROPs | 64 | 64 | 56 | ||
| Core Clock | 1126MHz | 1050MHz | 1050MHz | ||
| Boost Clock | 1216MHz | 1178MHz | 1178MHz | ||
| Memory Clock | 7GHz GDDR5 | 7GHz GDDR5 | 7GHz GDDR5 | ||
| Memory Bus Width | 256-bit | 256-bit | 256-bit | ||
| VRAM | 4GB | 4GB | 4GB | ||
| L2 Cache | 2MB | 2MB | 1.75MB | ||
| FP64 | 1/32 FP32 | 1/32 FP32 | 1/32 FP32 | ||
| TDP | 165W | 145W | 145W | ||
| GPU | GM204 | GM204 | GM204 | ||
| Transistor Count | 5.2B | 5.2B | 5.2B | ||
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 28nm | ||
| Launch Date | 09/18/14 | 09/18/14 | 09/18/14 | ||
| Launch Price | $549 | $329 | $329 | ||
When the GTX 980 and GTX 970 were released, NVIDIA provided the above original specifications for the two cards. The launch GTX 900 GPUs would be a standard full/die-harvested card pair, with the GTX 980 using a fully enabled GM204 GPU, while the GTX 970 would be using a die-harvested GPU where one or more SMMs had failed. As a result of this the big differences between the GTX 980 and GTX 970 would be a minor clockspeed difference, the disabling of 3 (of 16) SMMs, and a resulting reduction in power consumption. Most important for the conversation at hand, we were told that both possessed identical memory subsystems: 4GB of 7GHz GDDR5 on a 256-bit bus, split amongst 4 ROP/memory controller partitions. All 4 partitions would be fully active on the GTX 970, with 2MB of L2 cache and 64 ROPs available.
This, as it turns out, was incorrect.
As part of our discussion with NVIDIA, they laid out the fact that the original published specifications for the GTX 970 were wrong, and as a result the “unusual” behavior that users had been seeing from the GTX 970 was in fact expected behavior for a card configured as the GTX 970 was. To get straight to the point then, NVIDIA’s original publication of the ROP/memory controller subsystem was wrong; GTX 970 has a 256-bit memory bus, but 1 of the 4 ROP/memory controller partitions was partially disabled, not fully enabled like we were originally told. As a result GTX 970 only has 56 of 64 ROPs and 1.75MB of 2MB of L2 cache enabled. The memory controllers themselves remain unchanged, with all four controllers active and driving 4GB of VRAM over a combined 256-bit memory bus.
This revelation significantly alters how we perceive the performance of the GTX 970 in certain situations, and is the missing piece of the puzzle in understanding the memory allocation issues that originally brought all of this to light. The ability to “partially disable” a ROP/memory controller partition is new to Maxwell, and we’ll fully explore how that works in a moment, but the important part to take away is that the ROP/MC layout on the GTX 970 is not fully enabled like the GTX 980, and as a result will not behave identically to the GTX 980. All of the behavior from the GTX 970 we’ve seen in light of this correction now makes sense, and it is immediately clear that this is not a hardware or software bug in GTX 970, but rather the planned/intentional behavior of the product.
The biggest and most painful question about all of this then is how did this happen? How did we get fed incorrect specifications? NVIDIA’s explanation, in a nutshell, is that this was completely accidental and that all of this stems from assumptions made by NVIDIA’s technical marketing team.
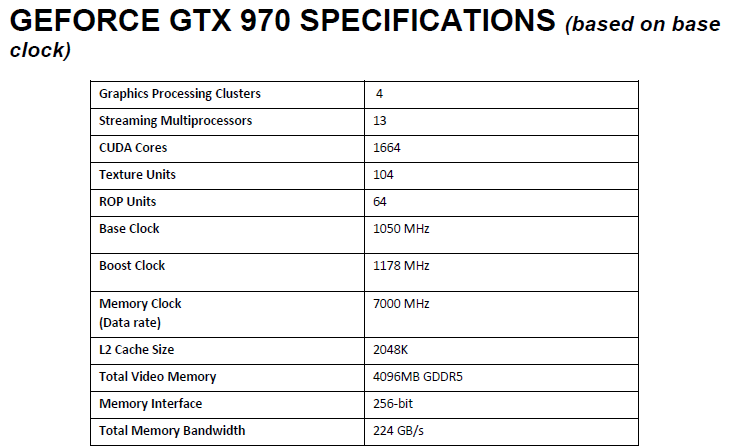
GTX 970 Reviewer's Guide: Specifications
In short, while NVIDIA does publish the specifications of their cards on the GeForce website and in other places (e.g. partner product pages), those are less-detailed high level specifications suitable for a wider audience, not unlike NVIDIA’s initial statement. The deeper technical specifications we get, such as the number of ROPs, transistor count, and L2 cache size, comes from NVIDIA’s reviewer’s guide, which outlines for us the specifications of the card, the major new features that NVIDIA is focusing on, and some examples of benchmark numbers they’re seeing. This document is compiled by NVIDIA’s technical marketing team (a group no less than extensively knowledgeable about GPUs) based on the information provided to them by the product engineers and the product management team.
The error, as NVIDIA explains it, is that in creating the GTX 970 reviewer’s guide, the technical marketing team was unaware of Maxwell’s aforementioned and new “partial disable” capabilities when they filled out the GTX 970 specification table. They were aware that the GTX 970 would have the full 256-bit memory bus, and unaware of the ability to independently disable ROPs they assumed that all 64 ROPs and the full 2MB of L2 cache was similarly available and wrote the specification table accordingly. This error then made it into the final copy of the guide, not getting caught even after being shared around various groups at NVIDIA, with that information finally diffused by press such as ourselves.
Somewhat murkier is the intervening 4 months between the launch of the GTX 970 and the discovery of this error. As NVIDIA tell us, since the error wasn’t caught in the initial check of the reviewer’s guide there weren’t any further checks being made, especially since this information wasn’t also distributed via a public source (such as the GeForce website). As far as technical marketing knew the product had 64 ROPs, and as far as product management and engineering knew the technical marketing team had done their due diligence. As a result this issue was not caught and identified at NVIDIA until earlier this month when NVIDIA technical marketing started investigating the reports and requests from the press about the memory allocation oddities. Only after running similar tests and running into the same odd results as the press and users did NVIDIA properly identify the issue.
GTX 970 Memory Allocation (Image Courtesy error-id10t of Overclock.net Forums)
Now as NVIDIA is in full damage control mode at this point, consideration must be given as to whether NVIDIA’s story is at all true; NVIDIA would hardly be the first company to lie when painted into a corner by controversy. With that in mind, given the story that NVIDIA has provided, do we believe them? In short, yes we do.
To be blunt, if this was intentional then this would be an incredibly stupid plan, and NVIDIA as a company has not shown themselves to be that dumb. NVIDIA gains nothing by publishing an initially incorrect ROP count for the GTX 970, and if this information had been properly presented in the first place it would have been a footnote in an article extoling the virtues of the GTX 970, rather than the centerpiece of a full-on front page exposé. Furthermore if not by this memory allocation issues then other factors would have ultimately brought these incorrect specifications to light, so NVIDIA would have never been able to keep it under wraps for long if it was part of an intentional deception. Ultimately only NVIDIA can know the complete truth, but given what we’ve been presented we have no reason to doubt NVIDIA’s story.
In any case, going forward NVIDIA has made it clear that they intend to make sure this doesn’t happen again, to make sure that the specifications released to the press and public are better checked to ensure nothing is inaccurate or being assumed. NVIDIA rarely makes the same mistake twice, and certainly they will be under a great deal more scrutiny from here on to make sure their published specifications are correct.
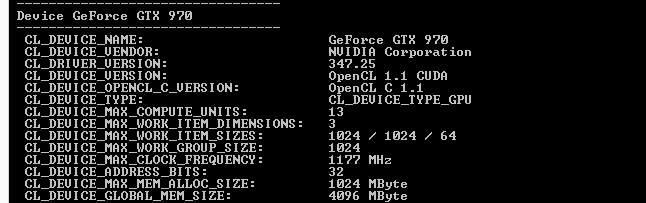
Meanwhile as press we play a role in this as well, as in retrospect we should have seen this sooner. Nebulous metrics such as VRAM allocation aside, NVIDIA’s own tools and our own experiences pointed to something being off. The pre-GM204 version of NVIDIA’s DeviceQuery CUDA application, for example, correctly reports that the GTX 970 only has 1.75MB of L2 cache and the GTX 980 has 2MB of L2 cache, even if it doesn’t fully understand the makeup of the Maxwell 2 architecture.
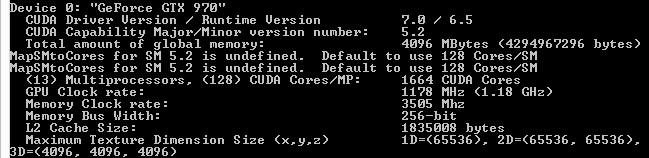
NVIDIA CUDA DeviceQuery: GTX 970
Furthermore our own initial incompatibility issues with the GTX 970 (and only the GTX 970) pointed to some kind of memory subsystem change that we should have looked into, even after NVIDIA corrected the problem in their drivers. Ultimately other tools such as GPU-Z and AIDA64 weren’t able to catch the difference since they too did not know about Maxwell’s ability to disable the ROPs, so only a limited number of flags were raised, but nonetheless this is something we admittedly should have been able to catch had we noticed what was wrong.
Diving Deeper: The Maxwell 2 Memory Crossbar & ROP Partitions
Now that we have a basic understanding of the proper specifications of the GTX 970 we can dig deeper into its architecture and layout. As we mentioned previously, the GTX 970 ships with an unusual configuration, one we’ve never quite seen before. In it, thanks to a new feature of the Maxwell architecture, NVIDIA has been able to disable part of a ROP/Memory Controller partition, something that they could not do on Kepler or earlier generation designs. As a result of this the intended behavior of the GTX 970 is different than the GTX 980 or any theoretical Maxwell part with a completely disabled ROP/MC partition.
The biggest impact of this configuration is that it creates the segmented memory conditions NVIDIA outlined in their earlier statement. Due to performance issues from the unbalanced ROP/MC partition, NVIDIA segments the memory into a high-performance 3.5GB segment – what they refer to as segment 0 – and a low-performance 512MB (0.5GB) segment containing the rest of the RAM. It is this segmentation that results in some of the previously-unusual memory allocation behaviors and memory bandwidth benchmarks on the GTX 970.
But in order to understand just why the segments exist, how they are allocated, and how they influence performance, we first need to learn about the Maxwell memory crossbar.
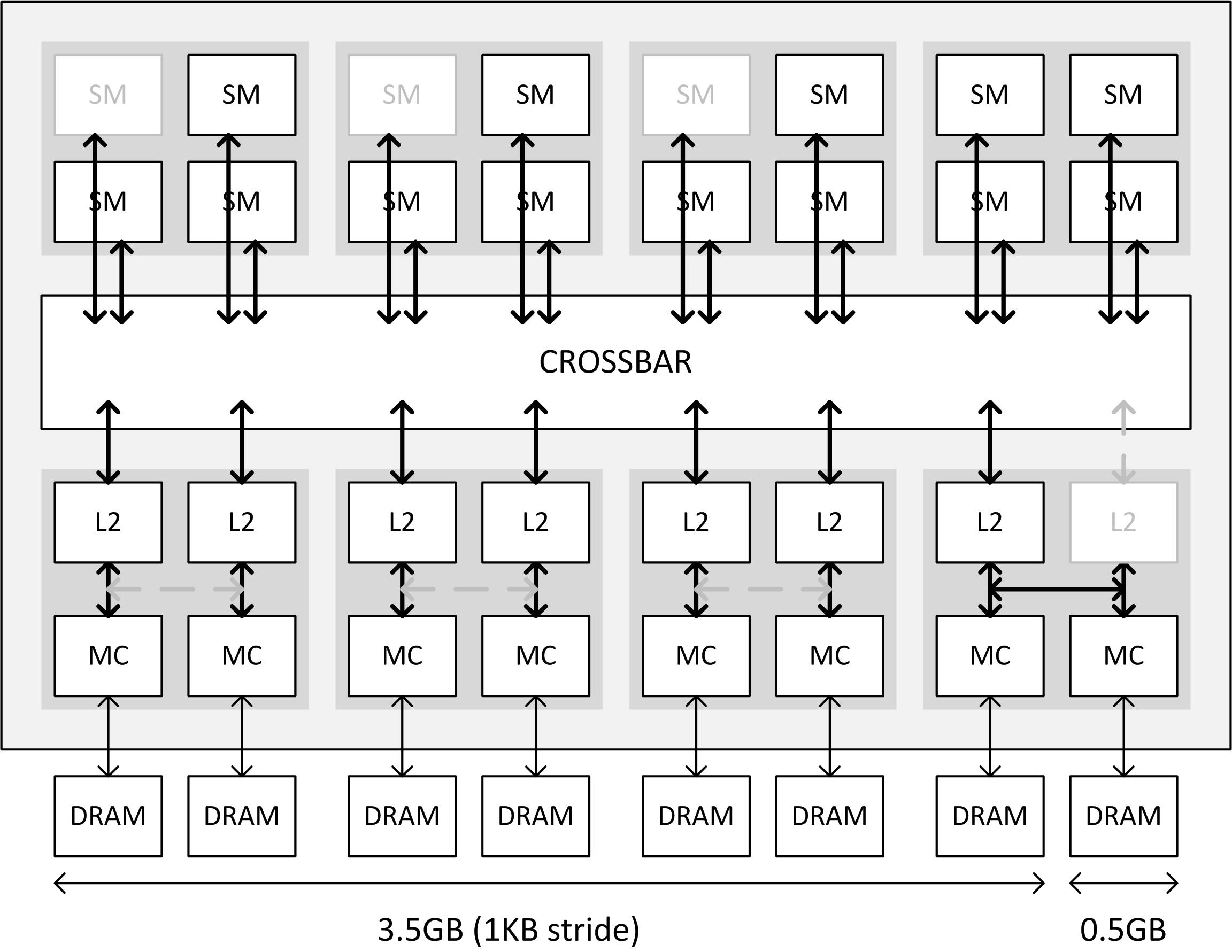
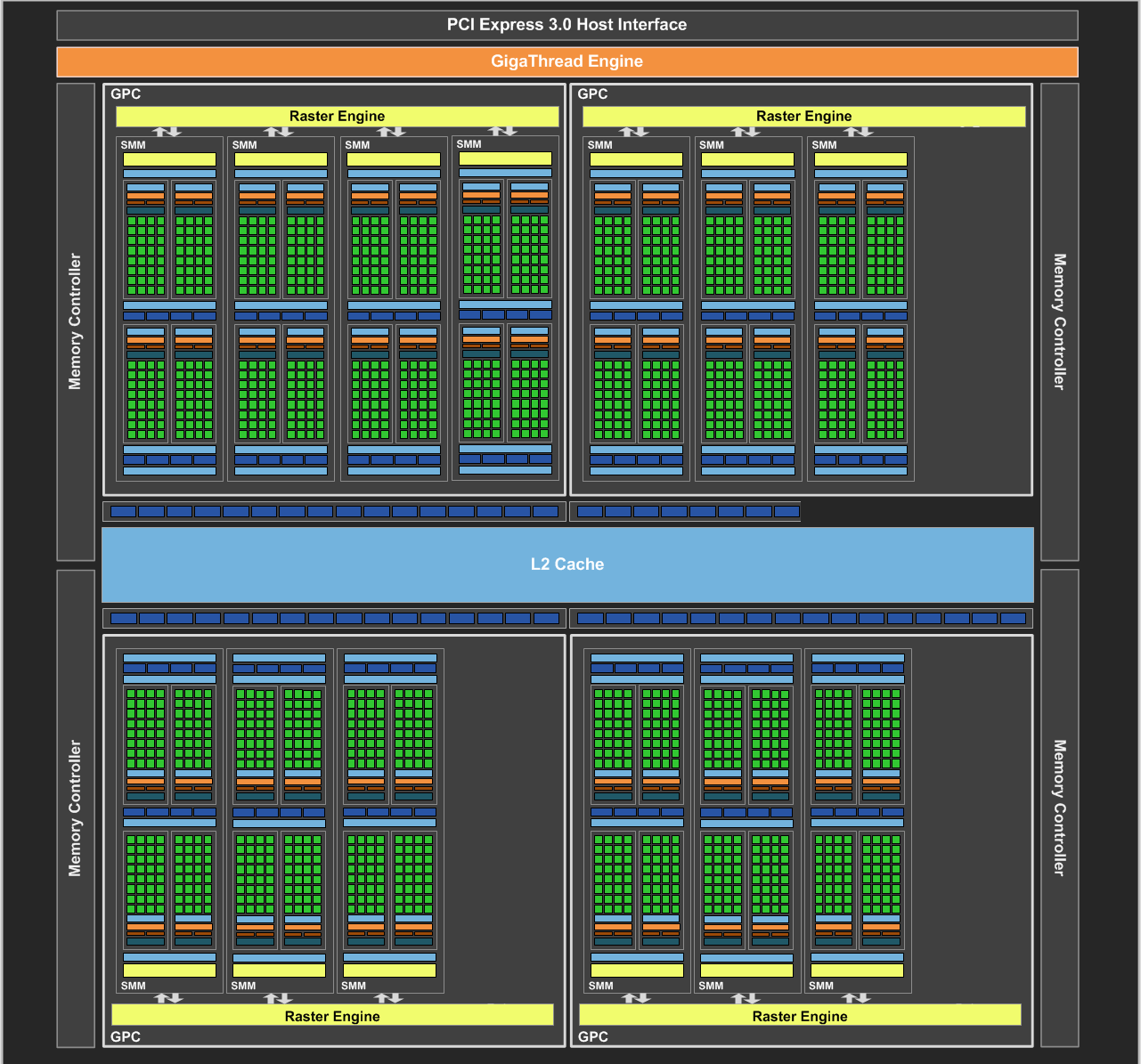
GTX 970 Memory Crossbar
In the above diagram from NVIDIA, NVIDIA illustrates at a high-level overview how the Maxwell memory crossbar is laid out, and specifically how it’s configured for GTX 970. In it we have the 16 GM204 SMMs at the top connected to the crossbar, meanwhile below we have 4 ROP/MC partitions, with each partition divided up into individual ROP/L2 units and memory controllers. Note that the specific units disabled on any GTX 970 chip will vary – it’s not necessarily the 1/3/5 SMMs or the last ROP/MC partition – but from a high level overview this is consistent for GTX 970 regardless of which specific physical units have been disabled.
In any case, while the crossbar shows how the SMMs and ROP/MC partitions are connected via the crossbar, memory segmentation is really a story about the ROP/MC partitions. The SMMs do not play a role in how GTX 970’s memory is configured – the crossbar abstracts all of that – and the crossbar itself matters only in as much as the ROP/MC partitions are connected to it.
When it comes to the ROP/MC partitions then, we can see first-hand in the GTX 970 what’s new in the architecture. In Kepler and previous generation designs, NVIDIA’s granularity for disabling ROP/MC partitions was all or nothing – either the entire partition was turned on or the entire partition was turned off. However starting with Maxwell, NVIDIA has gained the ability to disable the individual ROP/L2 units within a partition, allowing one of the two ROP/L2 units to be disabled. This essentially introduces a 3rd possible option: a partially-enabled ROP/MC partition, backed by two memory controllers and a single ROP/L2 unit. Meanwhile the memory controllers are still tied together, and disabling one of them requires disabling the entire partition.
| NVIDIA ROP/Memory Controller Configuration Options | |||
| Kepler | Maxwell | ||
| ROP/MC Partition Fully Enabled | ROP/MC Partition Fully Enabled | ||
| N/A | ROP/MC Partition Partially Disabled | ||
| ROP/MC Partition Fully Disabled | ROP/MC Partition Fully Disabled | ||
It’s this option that the GTX 970 leverages, and in doing so becomes the first Maxwell part to use this feature. NVIDIA has disabled 1 ROP/L2 unit, removing 8 “ROPs” (or rather 1 unit capable of 8 pixels/clock) and 256KB of L2 cache from the GTX 970. This is why the GTX 970 is left with 56 ROPs spread over the 4 partitions, along with 1.75MB of L2 cache.
Meanwhile there’s one other new feature here that’s activated only on the partially disabled partition, and that’s the link between the first and second units of the ROP partition. Typically each ROP/L2 unit would have a link to a port on the crossbar and a link to its own dedicated 32-bit memory controller channel; however because GTX 970 disabled a ROP/L2 unit, the “buddy” link comes in to play. This link is essentially the lynchpin of Maxwell’s new partial disable functionality, and allows the second half of the memory controller to stay active. This link only needs to be active when a ROP/L2 unit is disabled, and NVIDIA has confirmed that it is a full bandwidth link identical to the normal ROP/L2 to MC link, meaning it’s capable of 4 32 byte requests per clock (2 reads and 2 writes). Ultimately this link is what makes a partially disabled partition possible, and is also what makes it possible to have the full 256-bit memory bus present and active in spite of the lack of a ROP/L2 unit and its associated crossbar port.
Finally, because of this configuration and the lack of a ROP/L2 unit we get to the memory segments. Although the full 256-bit memory bus is present and active on GTX 970 and capable of providing 224GB/sec of combined memory bandwidth between the DRAM modules and the memory controllers, it’s a bit of a misnomer to say the card has that much bandwidth between the memory controllers and everything else, at least in the same sense that the GTX 980 does.
Like virtually every other operation on a GPU, memory accesses are done in parallel to improve throughput. On a fully enabled card such as GTX 980 these operations are striped across all of the memory controllers in what NVIDIA calls a 1KB stride. In doing this, each and every 32 bit memory channel needs a direct link to the crossbar through its partner ROP/L2 unit. However in the case of the GTX 970 a wrench is thrown into the works, as there are 7 crossbar ports and 8 memory channels.
Ultimately due to the design of the crossbars and the memory controllers, it is not possible for 1 crossbar port to carry the full load of 2 memory channels in all circumstances. The crossbar port and its attached ROP/L2 unit can access both memory channels at once, splitting up the 4 operations among them, but there is only 1 read return bus and 1 write data bas, and hence in practice it cannot issue identical operations to both memory channels at once . As a result NVIDIA has segmented the GTX 970’s memory into the now-familiar 3.5GB and 512MB segments. In the case of the 3.5GB segment, this behaves otherwise identically to a fully enabled card such as the GTX 980, with the 1KB stride being striped over 7 crossbar ports, and hence 7 DRAM modules. Meanwhile the 8th and final DRAM module sits in its own 512MB segment, and must be addressed by the crossbar on its own.
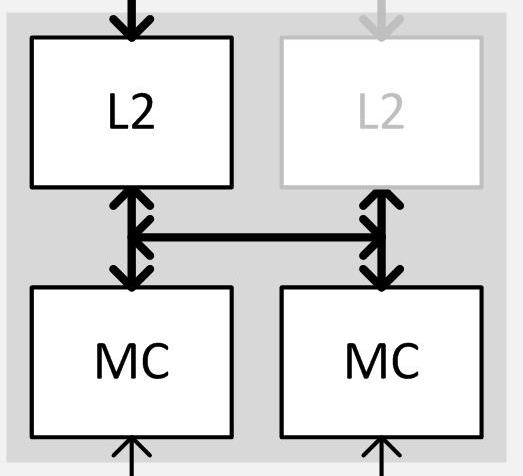
This in turn is why the 224GB/sec memory bandwidth number for the GTX 970 is technically correct and yet still not entirely useful as we move past the memory controllers, as it is not possible to actually get that much bandwidth at once when doing a pure read or a pure write. In the case of pure reads for example, GTX 970 can read the 3.5GB segment at 196GB/sec (7GHz * 7 ports * 32-bits), or it can read the 512MB segment at 28GB/sec, but it cannot read from both at once; it is a true XOR situation. The same is also true for writes, as only one segment can be written to at a time.
Unfortunately what this means is that accessing the weaker 512MB segment blocks access to the stronger 3.5GB segment if both memory operations are identical; or put another way, using the 512MB segment can harm the performance of the 3.5GB segment. For example, if we want to issue reads to both segments at once, reading the 512MB segment blocks any other reads to the 3.5GB segment for that cycle. If the 3.5GB segment is blocked in this fashion and doesn't have a non-blocking write to work on instead, it would have to go idle for that cycle, which would reduce the effective memory bandwidth of the 3.5GB segment. This means that taken over time in our example, the larger the percentage of the time the crossbar is reading the 512MB segment, the lower the effective read memory bandwidth would be from the 3.5GB segment.
Despite all of this, achieving peak memory bandwidth performance on the GTX 970 is still possible, but it requires much more effort since simple striping will not do the trick. The easiest and most effective solution in this regard is to interleave reads and writes over the segments, such that one segment is writing while another segment is reading. Interleaving in this fashion allows both segments to work at once – avoiding the blocking effect of the shared read and write buses – and makes it more likely that both segments are doing useful work rather than waiting for their turn on an operation. However because this is only applicable to situations where more than 3.5GB of VRAM is in use and both segments are necessary, this means it's only theoretically possible to achieve 224GB/sec when more than 3.5GB of VRAM is in use. In any situations below 3.5GB we are de-facto limited to just the larger segment, in which case there are only 7 memory channels (196GB/sec) to stripe memory operations across. NVIDIA could of course interleave operations sooner than that and use both segments more often, but due to the blocking effect we've discussed before the performance hit from using the 512MB segment can quickly become greater than any gains.
The end result of all of this is that the GTX 970 has a unique memory layout that needs to be accounted for by the operating system and NVIDIA’s drivers, as the use of multiple segments adds a new level of complexity to optimizing memory performance. Unequal in size and performance, among the two segments the 3.5GB segment is a larger, faster, and otherwise more preferable segment to the 512MB segment. Which means from a logical hierarchical perspective, the 512MB segment essentially serves as an additional layer of memory between the main VRAM and system memory, being slower than the 3.5GB segment but offering almost 2x the performance of going out over the PCIe bus to system memory.
The upshot here is that while this is the first time NVIDIA has used this specific ROP/MC configuration in a product, this is not the first product they have designed with segmented or otherwise unbalanced memory configurations. Since the GTX 500 series, on some midrange SKUs NVIDIA has used unbalanced/asymmetrical memory configurations, most recently on the GTX 660 and GTX 660 Ti. In the case of both of those cards, NVIDIA utilized a 192-bit memory bus with 2GB of VRAM attached, which meant that some memory controllers had more VRAM attached to them than others. The end result as it turns out is very similar, and while NVIDIA has never explained in-depth how they handle memory allocation on those cards, it turns out that it’s very similar to GTX 970’s memory segmentation. Which is to say that NVIDIA actually has multiple generations of experience with segmented memory, and this is not the first time they have implemented it. Rather this is first time we’ve seen such a configuration on a high-performance card such as the GTX 970.
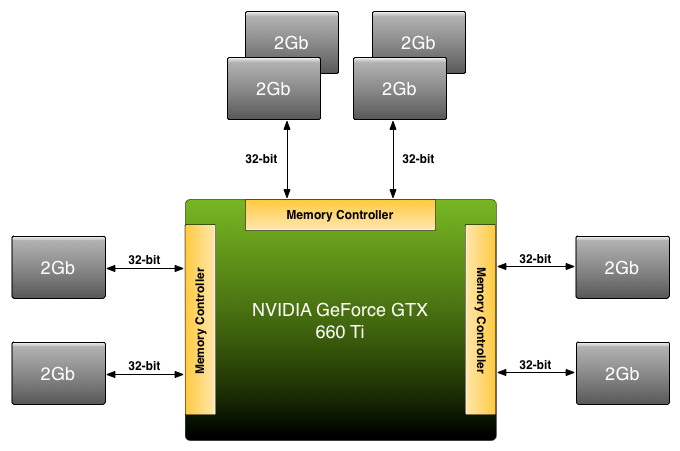
For Comparison: GTX 660 Ti's Unbalanced Memory Bus
| NVIDIA Maxwell Family Memory Controller Configurations | |||
| Part | Memory Segments | ||
| GTX 980 | 1 Segment (4x8 MC) | ||
| GTX 970 | 2 Segments (4x7 MC) | ||
| GTX 980M | 1 Segment (4x8 MC) | ||
| GTX 970M | 1 Segment (3x6 MC) | ||
| GTX 965M | 1 Segment (2x4 MC) | ||
As for why NVIDIA is using such a configuration here, the crux of the matter is money and yields. Without the ability to partially disable a ROP/MC partition, NVIDIA would either have to spec a card to use a fully enabled partition – essentially reducing yields for that card and driving up costs – or disable the entire partition and lose all of the benefits of the additional ROPs, memory, and the memory controller. This finer granularity allows NVIDIA to better control how they harvest bad chips and what resulting configurations they bring to market, along with making a single ROP/L2 defect less harmful to overall performance by keeping the rest of a partition online. Otherwise, to stick with a “balanced” configuration with as many crossbar ports as DRAM modules would result in either a higher spec GTX 970, or a lower spec card with a 192-bit memory bus.
In the grand scheme of things then, depending on how you want to define memory capacity the GTX 970 can be said to have either 3.5GB of VRAM or 4GB of VRAM. Only the first 3.5GB segment is a high-speed (full bandwidth) segment, and for naïve operations this is the segment that software will want to use. However the final 512MB segment is accessible, and despite its lower performance it is still usable and still far better than going to system memory, in which case GTX 970 has and can access a full 4GB of VRAM. This means that both answers can be correct, and like so many other facets of modern technology, the true answer is often more complex than a single number.
Segmented Memory Allocation in Software
So far we’ve talked about the hardware, and having finally explained the hardware basis of segmented memory we can begin to understand the role software plays, and how software allocates memory among the two segments.
From a low-level perspective, video memory management under Windows is the domain of the combination of the operating system and the video drivers. Strictly speaking Windows controls video memory management – this being one of the big changes of Windows Vista and the Windows Display Driver Model – while the video drivers get a significant amount of input in hinting at how things should be laid out.
Meanwhile from an application’s perspective all video memory and its address space is virtual. This means that applications are writing to their own private space, blissfully unaware of what else is in video memory and where it may be, or for that matter where in memory (or even which memory) they are writing. As a result of this memory virtualization it falls to the OS and video drivers to decide where in physical VRAM to allocate memory requests, and for the GTX 970 in particular, whether to put a request in the 3.5GB segment, the 512MB segment, or in the worst case scenario system memory over PCIe.
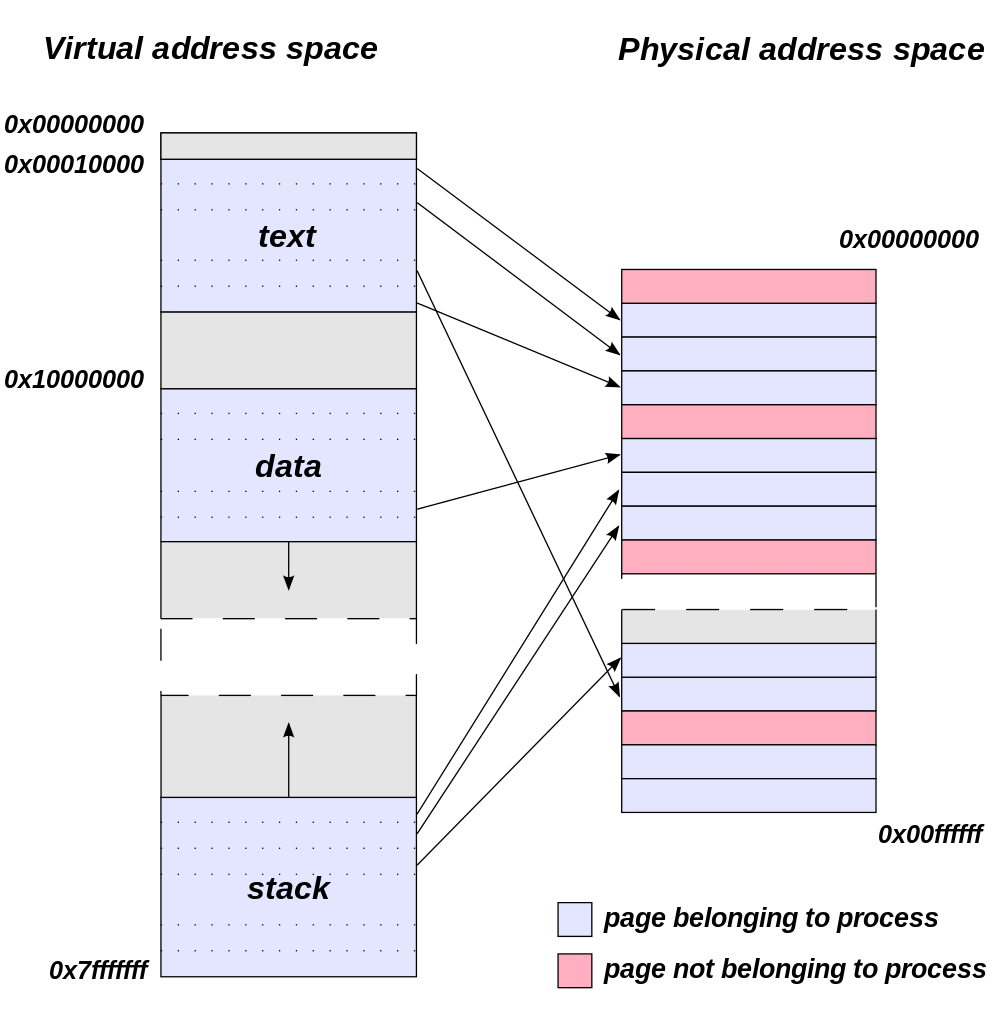
Virtual Address Space (Image Courtesy Dysprosia)
Without going quite so far to rehash the entire theory of memory management and caching, the goal of memory management in the case of the GTX 970 is to allocate resources over the entire 4GB of VRAM such that high-priority items end up in the fast segment and low-priority items end up in the slow segment. To do this NVIDIA focuses up to the first 3.5GB of memory allocations on the faster 3.5GB segment, and then finally for memory allocations beyond 3.5GB they turn to the 512MB segment, as there’s no benefit to using the slower segment so long as there’s available space in the faster segment.
The complex part of this process occurs once both memory segments are in use, at which point NVIDIA’s heuristics come into play to try to best determine which resources to allocate to which segments. How NVIDIA does this is very much a “secret sauce” scenario for the company, but from a high level identifying the type of resource and when it was last used are good ways to figure out where to send a resource. Frame buffers, render targets, UAVs, and other intermediate buffers for example are the last thing you want to send to the slow segment; meanwhile textures, resources not in active use (e.g. cached), and resources belonging to inactive applications would be great candidates to send off to the slower segment. The way NVIDIA describes the process we suspect there are even per-application optimizations in use, though NVIDIA can clearly handle generic cases as well.
From an API perspective this is applicable towards both graphics and compute, though it’s a safe bet that graphics is the more easily and accurately handled of the two thanks to the rigid nature of graphics rendering. Direct3D, OpenGL, CUDA, and OpenCL all see and have access to the full 4GB of memory available on the GTX 970, and from the perspective of the applications using these APIs the 4GB of memory is identical, the segments being abstracted. This is also why applications attempting to benchmark the memory in a piecemeal fashion will not find slow memory areas until the end of their run, as their earlier allocations will be in the fast segment and only finally spill over to the slow segment once the fast segment is full.
| GeForce GTX 970 Addressable VRAM | |||
| API | Memory | ||
| Direct3D | 4GB | ||
| OpenGL | 4GB | ||
| CUDA | 4GB | ||
| OpenCL | 4GB | ||
The one remaining unknown element here (and something NVIDIA is still investigating) is why some users have been seeing total VRAM allocation top out at 3.5GB on a GTX 970, but go to 4GB on a GTX 980. Again from a high-level perspective all of this segmentation is abstracted, so games should not be aware of what’s going on under the hood.
Overall then the role of software in memory allocation is relatively straightforward since it’s layered on top of the segments. Applications have access to the full 4GB, and due to the fact that application memory space is virtualized the existence and usage of the memory segments is abstracted from the application, with the physical memory allocation handled by the OS and driver. Only after 3.5GB is requested – enough to fill the entire 3.5GB segment – does the 512MB segment get used, at which point NVIDIA attempts to place the least sensitive/important data in the slower segment.
Practical Performance Possibilities
Last but not least, we would like to explore the potential performance repercussions of the GTX 970’s unusual configuration.
Starting with the ROPs, while NVIDIA’s original incorrect specification is unfortunate, from a practical perspective it’s really just annoying. As originally (and correctly) pointed out by The Tech Report and Hardware.fr, when it comes to fillrates the GTX 970 is already bottlenecked elsewhere. With a peak pixel rate of 4 pixels per clock per SMM, the GTX 970’s 13 SMMs inherently limit the card to 52px/clock, versus the 56px/clock rate for the card’s 56 ROPs. This is distinct from the GTX 980, where every stage of the GPU can pump out 64px/clock, and the ROPs can consume it just as well. In the case of the GTX 970 those extra ROPs still play a role in other tasks such as MSAA and other ROP activities that don’t require consuming additional SMM output – not to mention a fully disabled ROP/MC partition would shift the bottleneck to the ROPs with only 48 ROPs vs. 13 SMMs – so the 56 ROPs are still useful to have, but for basic pixel operations the GTX 970 has been bound by its SMM count from the start.
As for the memory segmentation, there are 3 basic scenarios to consider, only one of which has the potential to impact the GTX 970 in particular. In all cases with less than 3.5GB of memory allocated the GTX 970 behaves just as if it had a single segment, with no corner cases to be concerned about. Meanwhile in cases with more than 4GB of memory allocation the GTX 970 will still spill over to PCIe, just as the GTX 980 does, typically crushing performance in both cases. This leaves the last case as the only real concern, which is memory allocations between 3.5GB and 4GB.
| GeForce GTX 970 Theoretical Memory Bandwidth | |||
| Segment | Memory | ||
| Fast Segment (3.5GB) | 192GB/sec | ||
| Slow Segment (512MB) | 28GB/sec | ||
| PCIe System Memory | 16GB/sec | ||
In the case of memory allocations between 3.5GB and 4GB, what happens is unfortunately less-than-deterministic. The use of heuristics to determine which resources to allocate to which memory segment, though the correct solution in this case, means that the real world performance impact is going to vary on a game-by-game basis. If NVIDIA’s heuristics and driver team do their job correctly, then the performance impact versus a theoretical single-segment 4GB card should only be a few percent. Even in cases where the entire 4GB space is filled with in-use resources, picking resources that don’t need to be accessed frequently can sufficiently hide the lack of bandwidth from the 512MB segment. This is after all just a permutation on basic caching principles.
The worst case scenario on the other hand would be to have the NVIDIA heuristics fail, or alternatively ending up with a workload where no great solution exists, and over 3.5GB of resources must be repeatedly and heavily accessed. In this case there is certainly the potential for performance to crumple, especially if accessing resources in the slow segment is a blocking action. And in this case the GTX 970 would still perform better than a true 3.5GB card since the slow segment is still much faster than system memory, but it’s nonetheless significantly slower than the 3.5GB segment as well.

But perhaps the most frustrating scenario isn’t having more than 3.5GB of necessary resources, but having more than 3.5GB of unnecessary resources due to caching by the application. One VRAM utilization strategy for games is to allocate as much VRAM as they can get their hands on and then hold onto it for internal resource caching, increased view distances, or other less immediate needs. The Frostbite engine behind the Battlefield series (and an increasing number of other EA games) is one such example, as it will opportunistically allocate additional VRAM for the purpose of increasing draw distances. For something like a game this actually makes a lot of sense at the application level – games are generally monolithic applications that are the sole program being interacted with at the time – but it makes VRAM allocation tracking all the trickier as it obfuscates what a game truly needs versus what it merely wants to hold onto for itself. In this case tracking resources by usage is still one option, though like the overall theme of real world performance implications, it’s going to be strongly dependent on the individual application.
In any case, the one bit of good news here is that for gaming running out of VRAM is generally rather obvious. Running out of VRAM, be it under normal circumstances or going over the GTX 970’s 3.5GB segment, results in some very obvious stuttering and very poor minimum framerates. So if it does happen then it will be easy to spot. Running out of (fast) VRAM isn’t something that can easily be hidden if the VRAM is truly needed.
To that end in the short amount of time we’ve had to work on this article we have also been working on cooking up potential corner cases for the GTX 970 and have so far come up empty, though we’re by no means done. Coming up with real (non-synthetic) gaming workloads that can utilize between 3.5GB and 4GB of VRAM while not running into a rendering performance wall is already a challenge, and all the more so when trying to find such workloads that actually demonstrate performance problems. This at first glance does seem to validate NVIDIA’s overall claims that performance is not significantly impacted by the memory segmentation, but we’re going to continue looking to see if that holds up. In the meantime NVIDIA seems very eager to find such corner cases as well, and if there are any they’d like to be able to identify what’s going on and tweak their heuristics to resolve them.
Ultimately we find ourselves going a full circle back to something NVIDIA initially said about the matter, which is that the performance impact of the GTX 970’s configuration is already baked into the results we have. After all, the configuration is not a bug or other form of unexpected behavior, and NVIDIA has been fully abstracting and handling the memory segments since the GTX 970’s initial launch. So while today’s revelation gives us a better understanding of how GTX 970 operates and what the benefits and drawbacks are, that information alone doesn’t change how the card behaves.

Closing Thoughts
Bringing things to a close, I must admit I was a bit taken aback when NVIDIA first told us that they needed to correct the specifications for the GTX 970. We’ve had NVIDIA decline to disclose sensitive information before only to reveal it later, but they’ve never had to do something quite like this before. In retrospect these new specifications make more sense given the performance and device specs we’re seeing, but it certainly is going to leave egg on NVIDIA’s face as this never should have happened in the first place.
As for the GTX 970’s underlying memory configuration and memory allocation techniques, this is going to be a more difficult matter to bring closure to. Without question the GTX 970’s unusual memory configuration introduces a layer of complexity that isn’t there with the GTX 980, and as a result it’s extremely difficult to quantify better and worse in this case. It’s worse than the GTX 980 – and it is a lower tier card after all – but how much worse is no longer an easy answer to provide.
At its heart the GTX 970’s configuration is a compromise between GPU yields, card prices, and memory capacity. The easiest argument to make in that regard is that it should have shipped with a full 64 ROP configuration and skipped all of these complexities entirely. But on the whole and looking at the options for configurations without this additional complexity, a 3GB/48 ROP GTX 970 would have been underspeced, and with so much of the GTX 970’s success story being NVIDIA’s ability to launch the card at $329 I’m not sure if the other option is much better. At least on paper this looks like the best compromise NVIDIA could make.
In the end while I am disappointed that these details haven’t come out until now, I am satisfied that we now finally have enough information in hand to truly understand what’s going on with the GTX 970 and what its strengths and weaknesses are as a result of memory segmentation. Meanwhile for real world performance, right now this is an ongoing test with the GTX 970. As the highest-profile card to use memory segmentation it’s the first time NVIDIA has been under the microscope like this, but it’s far from the first time they’ve used this technology. But so far with this new information we have been unable to break the GTX 970, which means NVIDIA is likely on the right track and the GTX 970 should still be considered as great a card now as it was at launch. In which case what has ultimately changed today is not the GTX 970, but rather our perception of it.







{kind=link}